JARVIS Gets a Real Job
By David Rogers
I Said No to the Mac Mini
Then I bought the Mac mini.
I know. Last post I was fairly clear on this. The Mac mini was convenience spending, not problem solving. The constraint was VRAM, not the machine. I'd committed to a GPU. I said it in writing, which is the sort of thing I then have to live with.
A week later I'm unboxing an M4 Pro. The logic shifted, not because I changed my mind about the principle, but because the Mac mini silicon genuinely changes the maths. Unified memory means the GPU and CPU share the same pool. No discrete VRAM ceiling. 24 gigabytes available to the model, and the form factor fits the shelf above the router without requiring a second power board. It wasn't convenience. It was the right tool, and I'd been stubborn about it.
The rsync babysitting problem from last time, the one where I spent an evening watching a terminal because I hadn't built the thing that was supposed to prevent that, was supposed to be solved. Hardware sorted. Ollama installed. OpenClaw connected. JARVIS online.
That's how it was supposed to go.
The Docs Lied
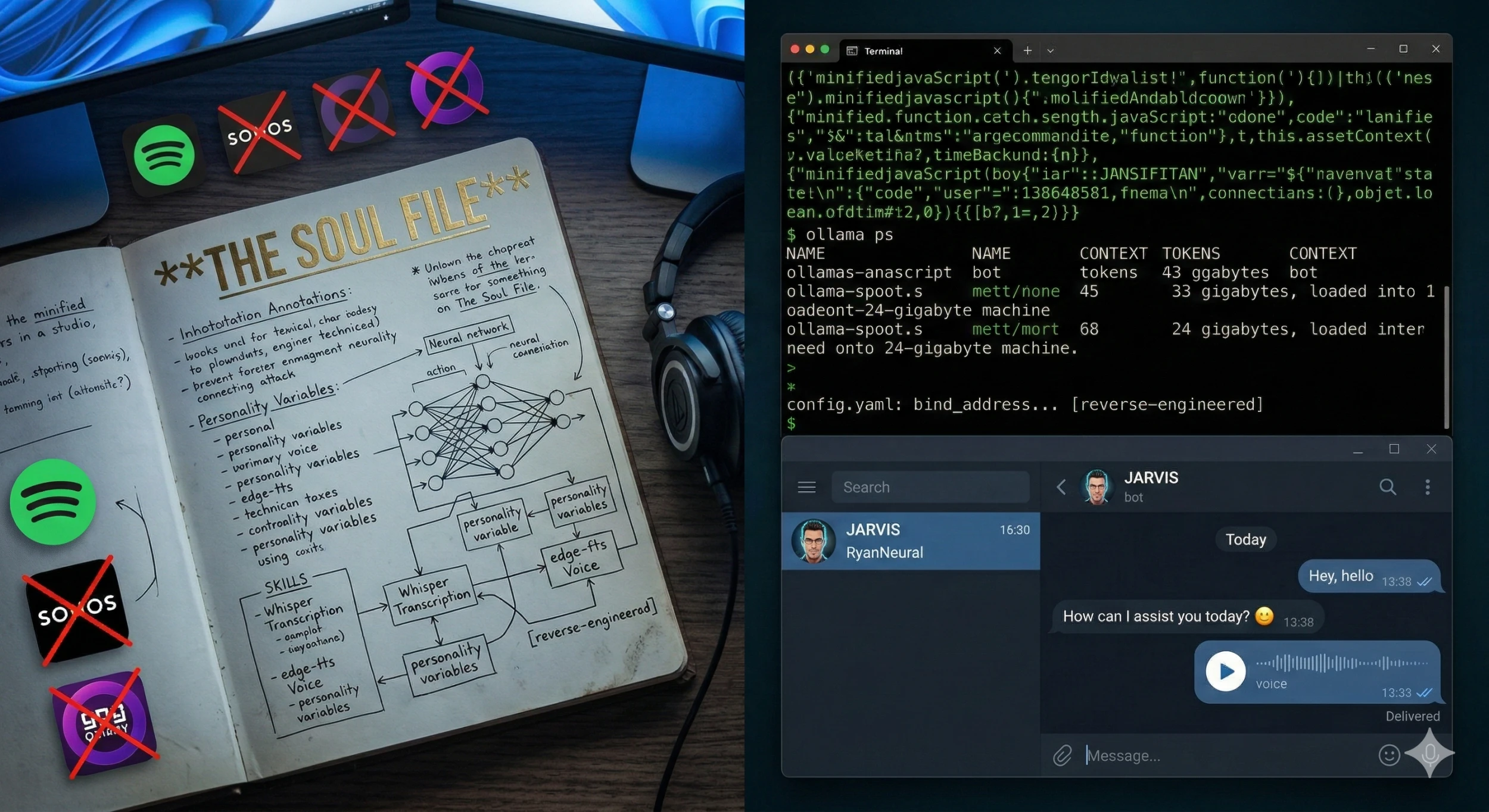
OpenClaw is the open-source agent framework sitting between the language model and the outside world. Telegram comes in, JARVIS processes it, a response goes back out. In theory it's the connective tissue. In practice, the documentation is wrong in at least six places, the config schema doesn't match what the installer actually produces, and the onboarding wizard exits with errors it caused itself.
I spent a Saturday evening reverse-engineering the bind address, the gateway token, the Ollama API mode, and the models array from minified JavaScript. Not because I wanted to. Because the docs told me one thing and the software did another, and at some point you stop refreshing the documentation and start reading the source.
It connected. Telegram sent a message. JARVIS was alive.
Six minutes later, a response appeared.
The Six-Minute Problem
Six minutes is a long time to wait for "How can I assist you today? 😊"
I watched ollama ps show 131,072 tokens of context — 33 gigabytes — being loaded onto a 24-gigabyte machine. Half the model falling off the GPU. I watched the typing indicator time out and reset. Twice. There were two root causes, and neither of them were in any tutorial I'd read.
The first: Qwen3's hidden thinking mode. Before every response, the model generates a silent internal monologue. A chain-of-thought scratchpad that runs before a single word appears in the reply. Nobody documents this. It's not off by default. You find it after an hour of watching a cursor blink with increasing personal frustration.
The second: 52 default skills loaded into context on every message. Spotify. Discord. Sonos. GOG Galaxy. Skills for services I don't use, have never used, and have no intention of using, all eating the context window before JARVIS had processed a word of what I'd actually asked.
Disabled 47 of them. Turned off the thinking mode. Context dropped from 100% to 59%. Response time went from six minutes to two. The hardware was fine. The default configuration had assumed I wanted a generic assistant, not a specific one.
It Got a Voice
Once it was responding in under two minutes, I started building out the thing I'd actually wanted: ambient I/O. Voice in, voice out.
The inbound side uses Whisper. OpenAI's open-source transcription model, running locally via Homebrew. Send a voice note to Telegram, Whisper transcribes it before the model sees it. No cloud, no API key. The outbound side uses edge-tts, which calls Microsoft's neural voice service and sends back an audio file as a Telegram voice message. Not entirely on-prem, I'll be honest about that, but for a private assistant that already has internet access, it's an acceptable trade for the voice quality you get.
I auditioned 28 English voices by batch-sending them all to Telegram. Spent a strange twenty minutes listening to different versions of the same phrase delivered by slightly different synthetic people. The Australian voice — William — didn't feel right. Too familiar, somehow. I landed on en-GB-RyanNeural. British male, calm, unhurried.
The first time I sent a voice note and got one back, I sat in my office for a moment and didn't say anything. It worked. After three days of config hell and a Saturday night arguing with minified JavaScript, JARVIS answered me in a voice I'd chosen, with words built from a model running on my own hardware, delivered to my phone through a bot I'd connected myself.
It still ended the message with "How can I assist you today? 😊". Work in progress.
The Constraint Was Never the Hardware
Here's what actually shifted.
The VRAM problem is gone. Devstral 24B runs fully on GPU. The Mac mini handles it cleanly. But the thing blocking JARVIS from being useful wasn't VRAM; it was the assumption baked into every default that you want a general-purpose assistant. Fifty-two skills. A hidden thinking mode. A context window that eats itself before you've said hello. The software assumed you weren't specific.
Fixing that isn't a config task. It's a design task. And it starts with something I've been calling the soul file, a document that defines not just what JARVIS does, but how it thinks, what it prioritises, what it sounds like, and what it declines to be.
That's where we're headed. The hardware is sorted. The plumbing is running. The real question now is whether a local model can actually hold a specific personality under pressure, not the default, not the trained persona, but the one you've written for it.
That's personality matching in practice, not theory. And I don't know yet if it works.
Next up: the soul file, and whether a small local model can actually hold a specific identity — or whether it just keeps offering to assist you today with a smile emoji.